Cini Francesco – Architettura degli elaboratori
LA CACHE
La memoria di un calcolatore è formata da varie di sequenze di
celle di dimensioni variabili e può
essere suddivisa in diversi tipi: cache, memoria principale e memoria di massa.
La memoria interna è composta in piccola parte da memoria di sola
lettura (ROM) e da memoria di lettura-scrittura (RAM) che può essere suddivisa
in due tipi: DRAM e SRAM.
La memoria di massa invece è un tipo di memoria non volatile che
permane una volta scritta, e può essere ad esempio un hard disk, un cd rom, un
dvd etc..
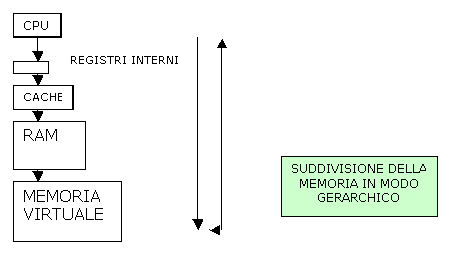
La RAM sebbene sia veloce non lo è abbastanza da riuscire a seguire i moderni processori, quindi il
processore perderebbe troppo tempo ad aspettare l’arrivo dei dati dalla
memoria. Al fine di ottenere migliori prestazione con il minor costo possibile
si è venuta a creare la necessità di suddividere la memoria in modo gerarchico
con sopra le memorie più piccole e veloci (cache), e sotto con memorie più
ampie ma più lente (RAM, memoria virtuale).
Tipicamente
la memoria cache è da 20 a 100 volte più piccola della memoria centrale ma è
anche da 5 a 20 volte più veloce.
![]()
![]()
![]()

L’utilità
della cache è quindi quella di fare rimanere in memoria i dati che il
processore usa più spesso, e la prima
volta che la cpu carica dei dati dalla memoria centrale, questi vengono
caricati anche sulla cache e le volte successive, i dati
possono essere letti dalla cache più
velocemente invece che dalla memoria centrale che è più lenta.
Le cache sono suddivise in due livelli e quando si parla di cache,
si fa normalmente riferimento alla cache di secondo livello (L2), chiamata
anche cache esterna, mentre le cache di primo livello (L1) sono quelle
integrate direttamente sulle cpu. La cache L2 è da sempre composta da SRAM, un
tipo di memoria molto veloce e costosa. Il tempo di accesso medio va dai 10 ai
25 nanosecondi. La maggiore velocità è dovuta al fatto che non è necessario
fare il refresh del contenuto della cella (come nelle DRAM) visto che
quest'ultima è composta da due transistor collegati in modo da ritenere lo
stato(0 o 1) fintantoché l'alimentazione esterna è mantenuta. La cache funge da
memoria di transito fra la RAM centrale e la CPU. Ogni volta che quest'ultima
preleva informazioni dalla RAM, ne è riprodotta una copia che finisce nella
cache per essere immediatamente reperibile per qualsiasi accesso successivo,
nella cache sono copiate inoltre le informazioni che in memoria sono adiacenti
al dato appena richiesto così che nelle successive operazioni la CPU non debba
più accedere alla RAM ma possa servirsi direttamente dalla cache, ben più
veloce.
Storicamente le CPU sono sempre state più veloci delle memorie. Quando le
memorie sono migliorate, lo hanno fatto anche le CPU, mantenendo la distanza.
In realtà il problema non è tecnologico ma economico infatti si potrebbero
costruire memorie veloci quanto le CPU, ma sarebbero così costose che dotare un
computer con un megabyte o più di cache sarebbe economicamente improponibile.
Così si è scelto di avere una piccola quantità di memoria veloce ed una gran
quantità di memoria lenta.
I programmi riutilizzano dati e istruzioni che hanno usato di
recente, quindi un programma spende circa il 90% del suo tempo di esecuzione
per solo il 10 % del suo codice, e questo è noto come principio di località che sta alla base di tutti i sistemi di
cache. La località può essere temporale
(quando un programma che richiede un dato lo richieda nuovamente entro breve
tempo), oppure spaziale (quando
un programma che accede ad un dato indirizzo richieda anche i suoi dati
vicini).
L’idea generale è che quando fatto riferimento ad una word, questa sia
trasferita dalla gran memoria lenta nella cache, così che sia accessibile
velocemente per successive utilizzazioni.
Ci sono 3 diversi tipi di memorie cache che usano differenti
tipologie di mappatura per copiare i dati della ram ad essa e sono: cache a
mappatura diretta, cache associativa, e cache parzialmente associativa (o a n
vie).
Il primo tipo, la cache a mappatura diretta (direct mapped cache) prevede che
una determinata linea di memoria venga mappata sempre stessa posizione di linea
in cache.


|
IB (blocco) Tag 24 bit |
IL(linea) Index 4 bit |
IW (parola) Offset 4 bit |
Esempio a 32 bit
Il campo IB ci dice in quale blocco appartiene l’indirizzo
specifico di memoria, ed è la parte più significativa dell’indirizzo.
il campo IL dell’indirizzo permette di identificare la linea in
RAM, mentre il campo IW ci indica la parola specifica ed è diviso in due parti.
Se l’indirizzo è a 32 bit un blocco memorizza 16 byte ossia 4
parole, e la cache ha 16 linee.
L’offset di blocco ha 4 bit i 2 bit meno significativi individuano
il byte all’interno della parola, gli altri 2 a sinistra individuano la parola
nel blocco.
L’indirizzo di blocco ha 24 bit che individuano il tag mentre i 4
bit successivi meno significativi individuano l’indice di linea.
Come si vede nella figura sopra a destra, la cache è composta da
due banchi di memoria distinti che lavorano in parallelo: Il banco DATA RAM e
il banco TAG RAM.
Il primo ha la funzione di contenere i dati, e ogni posizione di
data ram corrisponde ad una linea di cache ,mentre il secondo rappresenta il
catalogo dei dati contenuti sull’altro banco, e ogni posizione in tag ram ha
dimensione pari a quella del campo IB dell’indirizzo generato dalla CPU.
Se il processore richiede in cache un indirizzo dove ci sia un IB
e un IL uguali allora abbiamo un “Hit” e il segnale di “OE” rende
immediatamente disponibile la parola letta. Se così non fosse vuol dire che
l’indirizzo di memoria che cerchiamo non è in cache (miss) quindi bisogna
cercarlo sull’altra memoria.
Con Hit rate e Miss rate si indica la percentuale di trovare o
meno un dato in cache.
Il vantaggio della mappatura diretta è l’enorme semplicità infatti
la linea di memoria di ram è mappata nella stessa linea di cache
Gli svantaggi sono che non c’è nessuna liberta di scelta nel
piazzamento delle linee e quindi non si sfrutta a pieno la ampiezza della
cache, con la possibilità quindi di sovrascrivere più volte un dato, aumentando
quindi il miss rate.
Nella cache associativa
(fully associative cache) le linee di memoria possono essere mappate in
qualunque posizione, senza alcun riferimento al loro indirizzo.


Quindi dato
che la posizione della linea di cache non è più associata all’indirizzo di
linea ogni linea di memoria ha un indirizzo univoco (IX) che deve essere
memorizzato in tag ram. Non esiste quindi il campo “index”.
Il processore
confronta il campo IX tutti i campi in parallelo della tag ram, se coincide
avremo un hit, altrimenti avremo un miss.
A differenza
della mappatura diretta a fronte di un miss dobbiamo indivudiare quale linea
sostituire tra le linee possibili.
La ricerca
della linea in DATA RAM si avvia solo quando si è conclusa la ricerca in TAG RAM e i tempi di ricerca
non possono essere sovrapposti come nel caso della mappatura diretta, questo
comporta quindi un tempo più lungo.
I vantaggi di
questo tipo di cache sono che abbiamo la possibilità di mettere (con
determinate politiche di allocazione) le linee dove vogliamo, usando in pieno
tutto lo spazio di cache e riducendo quindi il miss rate.
Lo svantaggio
principale è che realizzare una cache di questo tipo è piuttosto complicato.
|
TAG 28 bit |
OFFSET 4 bit |
Esempio a 32 bit
Ci sono 3
principali politiche di allocazione per la cache associativa : LRU, FIFO e
RAND.
L’algoritmo
LRU (least recent used) consiste nel rimpiazzare tra tutte le linee quelle
usate meno di recente, e quindi un pezzo di codice poco frequentato
dall’esecuzione del programma.
Questa
modalità è molto complessa da realizzare e anche costosa.
L’algoritmo
FIFO (first in first out) consiste nel rimpiazzare il primo dato messo in cache
con l’ultimo, e questo è di media complessità realizzativa.
L’ultimo, il
RAND, consiste nel rimpiazzare le linee in modo casuale, tra i tre è il metodo
più facile da realizzare e dati sperimentali dimostrano che le prestazioni non
sono eccessivamente degradanti.
La cache
parzialmente associativa (o a n vie) prevede un funzionamento analogo alla
mappatura diretta, ma con più banchi di cache in cui poter trovare il dato,
ricucendo le possibilità di conflitti, inoltre ha un tag più grosso e un bit in
meno di linea.
E’ detta anche
cache associativa a più vie perché è come se utilizzasse più caches, infatti
ciascuna via si comporta come una cache a mappatura diretta, le due linee hit0
e hit1 abilitano l’uscita della via in cui si trova il dato.


|
IB (blocco) Tag 25 bit |
IL(linea) Index 3 bit |
IW (parola) Offset 4 bit |
Esempio a 32 bit
Se vogliamo calcolare il tempo di accesso medio dobbiamo fare
questo calcolo:
Tavg = HT x Hrate + MT x Mrate (sarebbe Tempo di “hit” x Hitrate + Tempo di
miss x Missrate) ad es. Tavg = 1 x 0,90 +
50 x 0,10 = 5,9 cicli di clock
Per aumentare le prestazioni occorre ridurre il tempo di accesso
alla cache, scegliendo dispositivi di cache ad alte prestazioni, poi ridurre il
miss penalty scegliendo dispositivi a prestazioni più alte utilizzando multipli
livelli di cache e aumentare la probabilità di hit.
Un altro fattore determinante sulle prestazioni di una cache e
dunque dell’intero sistema, sono le politiche di scrittura che sono
generalmente due: il Write-Back e il Write-trought.
·
Write-Back
La traduzione sta per “Scrivi dietro”, il senso, invece, è che il
dato una volta modificato viene memorizzato solamente sulla cache, la
memorizzazione sulla memoria principale avverrà solamente nel caso in cui il
dato debba essere scaricato.
·
Write-trought
Tradotto indica “scrivi attraverso”, cioè, la scrittura del dato
una volta che questo è stato modificato, avviene attraverso la cache. Infatti
il dato viene prima memorizzato sulla cache e poi dalla cache verrà subito dopo
memorizzato nella memoria principale.
Nell’implementazione di un sistema che supporti la cache, la
scelta di una o dell’altra politica viene principalmente fatta in base alla
dimensione dei blocchi della cache e alla larghezza di banda (frequenza con cui
i dati vengono trasmessi) tra
quest’ultima e la memoria principale, ovvero secondo la capacità del Bus.